
下面是对比 Pymupdf4llm 和 pdf-extract-api 两种工具在多个维度上的分析:
1. 工具介绍
• Pymupdf4llm
是基于 PyMuPDF 的轻量级库,用于解析 PDF 文档并将其输出为适合 LLM 使用的格式。主要侧重文本提取和结构化处理,适合生成上下文良好的段落,便于用于 LLM 的问答场景。
• pdf-extract-api
是一个基于 API 的工具,专注于从 PDF 中提取特定的数据(如表格、元数据、关键段落等)。它通常提供更精细的配置选项,且需要在线服务支持。
2. 优点
Pymupdf4llm
• 开源和轻量化:基于 PyMuPDF,依赖简单,不需要网络请求。
• 灵活性:支持本地化部署和定制,适合对隐私敏感的数据处理。
• LLM优化:文本提取经过优化,更适合直接喂给 LLM 使用。
• 社区支持:有 Python 社区的广泛支持,文档丰富。
pdf-extract-api
• 精确提取:通过 API 提供强大的功能,如识别表格、图像提取以及结构化内容分离。
• 便捷性:通常不需要用户过多了解 PDF 内部结构,适合快速实现提取目标。
• 扩展性:可与其他 API 组合实现复杂任务,如 OCR 集成处理扫描 PDF。
3. 缺点
Pymupdf4llm
• 复杂性有限:对非常复杂的 PDF(如多层嵌套、表格、图片)支持不如专业化工具。
• 手动调整需求高:对提取后的数据,需要编写代码进一步清洗和整理。
pdf-extract-api
• 依赖在线服务:需要网络访问,可能对敏感文档不适合。
• 成本问题:通常是收费服务,使用量大时费用可能较高。
• 上手门槛高:需要了解 API 调用的基础,复杂设置可能增加学习成本。
4. 准备度与上手难度
指标 Pymupdf4llm pdf-extract-api
部署与安装 安装简单(pip install pymupdf 等) 需要注册 API 服务并配置访问权限
学习曲线 易于上手,Python 开发者友好 需要熟悉 API 文档,配置参数稍复杂
定制化能力 高,代码灵活,自由控制输出内容和格式 中,定制需依赖 API 提供的接口和选项
速度 本地运行,速度快 API 请求受网络和服务端性能影响
环境依赖 本地运行,无需联网 需联网使用在线 API 服务
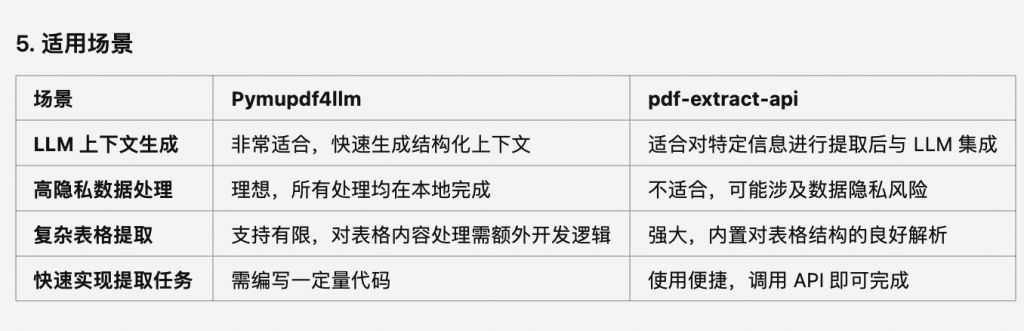
总结与建议
• 选择 Pymupdf4llm:
如果你希望完全掌控 PDF 的提取逻辑、对敏感数据有隐私保护需求,并倾向于本地化轻量部署,Pymupdf4llm 是不错的选择。
• 选择 pdf-extract-api:
如果需要快速处理复杂的 PDF 任务(如表格解析、精确提取特定内容),且不介意使用在线服务和支付一定费用,那么 pdf-extract-api 更加适合。
最终选择取决于项目的复杂性、隐私要求和开发资源。