什么是 Milvus?
Milvus 是一个开源的向量数据库,专为管理和检索大量向量数据而设计,广泛应用于人工智能、推荐系统、图像检索、自然语言处理等领域。它支持 PB 级别的数据存储,提供高性能的向量检索服务。
Milvus 的核心功能
1. 高效检索: 支持 ANN(近似最近邻)检索,适用于超大规模向量检索任务。
2. 多数据类型: 支持文本、图像、视频等多种嵌入向量数据。
3. 弹性扩展: 支持水平扩展和分布式部署。
4. 多种索引类型: 包括 IVF、HNSW、DiskANN 等。
5. 多语言 SDK 支持: 提供 Python、Java、Go、C++ 等多种 SDK。
6. 云原生架构: 支持 Kubernetes 部署,便于云上运行。
Milvus 的应用场景
1. 图像和视频检索(内容推荐)
2. 自然语言处理(语义检索与推荐)
3. 推荐系统(个性化推荐)
4. 生物医学数据分析(DNA 比对)
5. 安全监控(面部识别)
Milvus 快速上手教程
1. 环境准备
• 操作系统:Linux/macOS/Windows
• 安装 Docker(推荐)或 Kubernetes(用于生产环境)
2. 安装 Milvus
使用 Docker 快速启动:
docker pull milvusdb/milvus:latest
docker run -d –name milvus-standalone -p 19530:19530 -p 8080:8080 milvusdb/milvus:latest
3. 创建 Milvus 客户端
安装 Milvus Python SDK:
pip install pymilvus
4. 连接到 Milvus
from pymilvus import connections
connections.connect(
alias=”default”,
host=”localhost”,
port=”19530″
)
5. 创建集合与插入数据
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
# 定义字段
fields = [
FieldSchema(name=”id”, dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name=”embedding”, dtype=DataType.FLOAT_VECTOR, dim=128)
]
# 定义集合架构
schema = CollectionSchema(fields, “向量数据集合”)
# 创建集合
collection = Collection(“example_collection”, schema)
# 插入数据
import numpy as np
data = [
[i for i in range(1000)], # id
np.random.random([1000, 128]).tolist() # 随机向量
]
collection.insert(data)
6. 创建索引与检索
# 创建索引
index_params = {
“metric_type”: “L2”,
“index_type”: “IVF_FLAT”,
“params”: {“nlist”: 100}
}
collection.create_index(field_name=”embedding”, index_params=index_params)
# 搜索向量
search_params = {
“metric_type”: “L2”,
“params”: {“nprobe”: 10}
}
query_vector = np.random.random([1, 128]).tolist()
results = collection.search(
data=query_vector,
anns_field=”embedding”,
param=search_params,
limit=5
)
# 输出结果
for result in results[0]:
print(f”ID: {result.id}, Distance: {result.distance}”)
Milvus 官方资源
• 官网:Milvus 官方网站
• 文档:Milvus 文档中心
• GitHub:Milvus GitHub 仓库
如果需要更详细的教程或针对特定场景的使用指导,请告诉我!


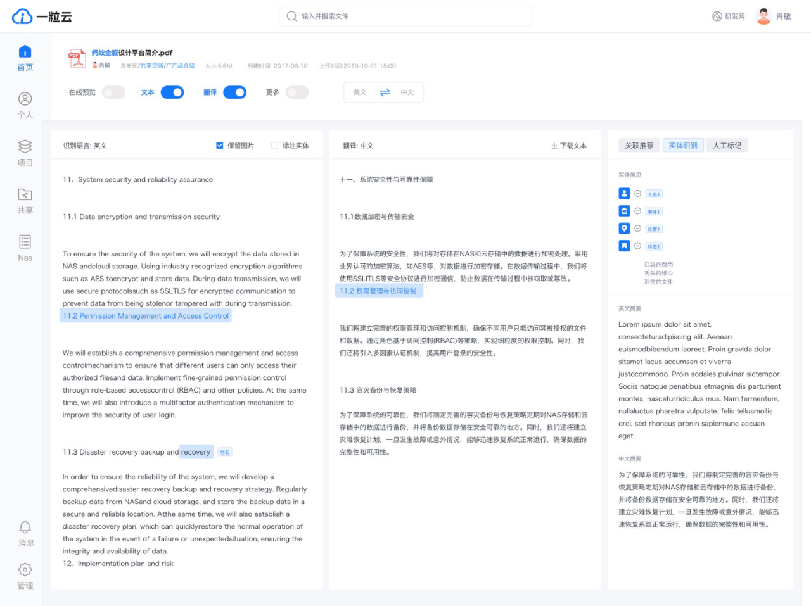

 全面的文件相似度分析,助力高效决策
全面的文件相似度分析,助力高效决策 智能化界面,操作便捷
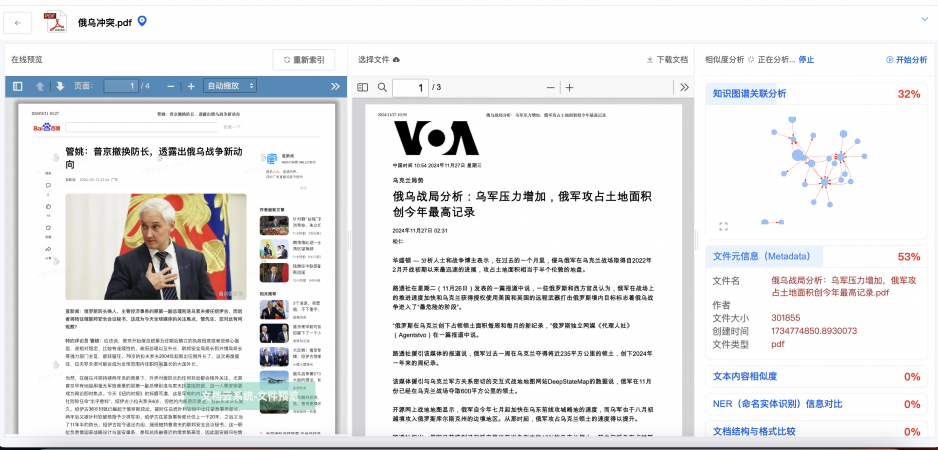
智能化界面,操作便捷 深度分析,助力精准决策
深度分析,助力精准决策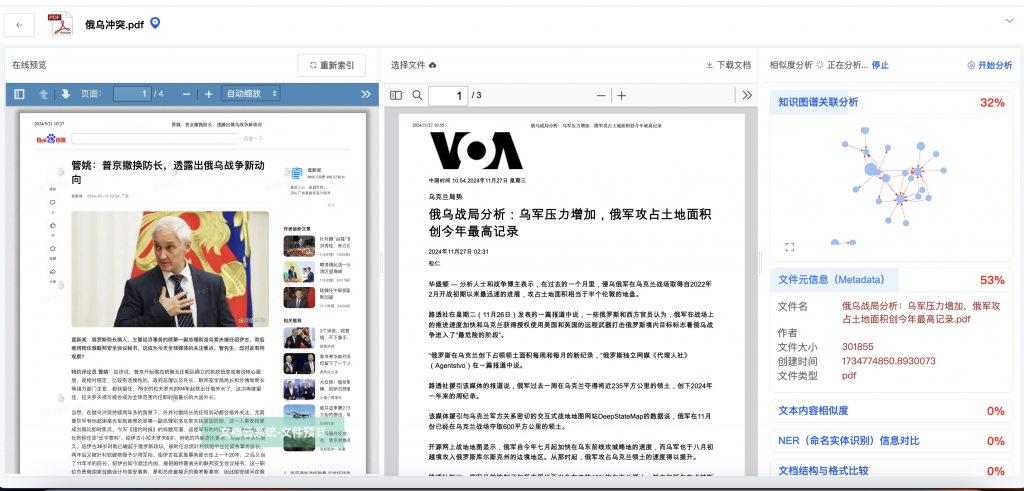
 从文件相似度到数据洞察,全面提升工作效率
从文件相似度到数据洞察,全面提升工作效率